
Microsoftから提供されている、AIChatWebプロジェクトテンプレートはユーザーの質問に対して、Embeddingモデルに登録されたPDFの内容から回答を導き出すAI Chatアプリケーションのプロジェクトテンプレート。
以下の方法でプロジェクトテンプレートをインストールできる。
> dotnet new install Microsoft.Extensions.AI.Templatesデフォルトではgithubmodelsを使用するようになっているが、今回はローカルのollamaで試してみた。
プロジェクトを作成するときに下記のようにすることで、LLMのプロバイダやLLMモデル,Embeddingモデルを指定できる。
> dotnet new aichatweb --provider ollama --vector-store local --ChatModel llama3.2:latest --EmbeddingModel all-minilm:22m -o <プロジェクト名>これでプロジェクトを作成すると、以下のようにProgram.csにLLMへの接続やモデルが自動的に反映される。また、Embeddingの設定等も自動的にされる。
using Microsoft.Extensions.AI;
using AIChatWebAppOllama.Components;
using AIChatWebAppOllama.Services;
using AIChatWebAppOllama.Services.Ingestion;
using OllamaSharp;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddRazorComponents().AddInteractiveServerComponents();
IChatClient chatClient = new OllamaApiClient(new Uri("http://localhost:11434"),
"llama3.2:latest");
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator = new OllamaApiClient(new Uri("http://localhost:11434"),
"all-minilm:22m");
・・・using Microsoft.Extensions.VectorData;
namespace AIChatWebAppOllama.Services;
public class IngestedChunk
{
private const int VectorDimensions = 384; // 384 is the default vector size for the all-minilm:22m embedding model
・・・このテンプレートではEmbeddingはPDFに限られ、wwwroot\Data下にあるPDFの内容が対象となる。
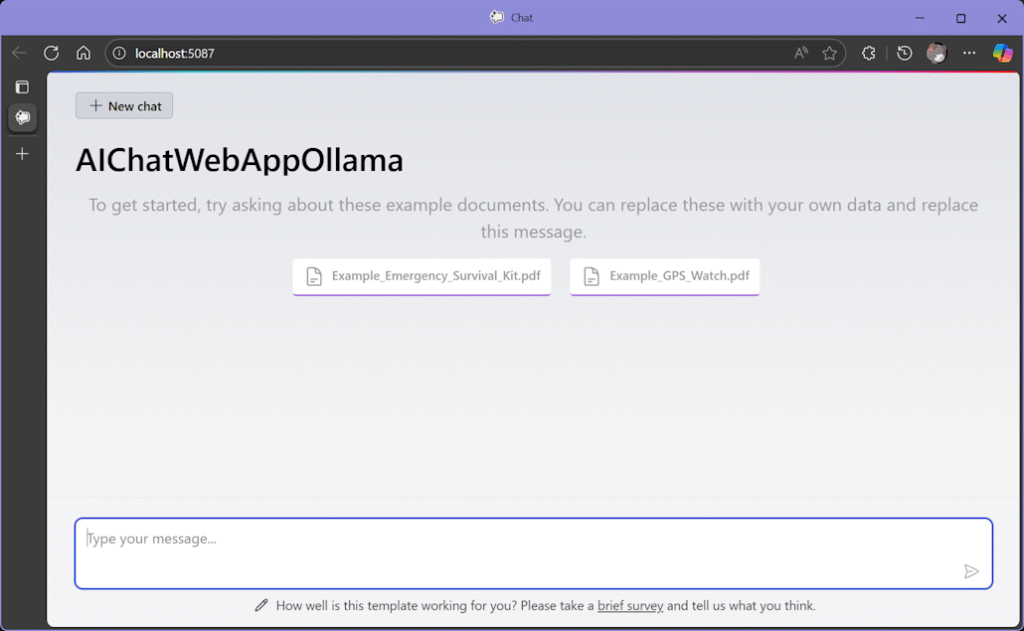
とりあえず、実行してみる。
「サバイバルキット」について質問してみると、
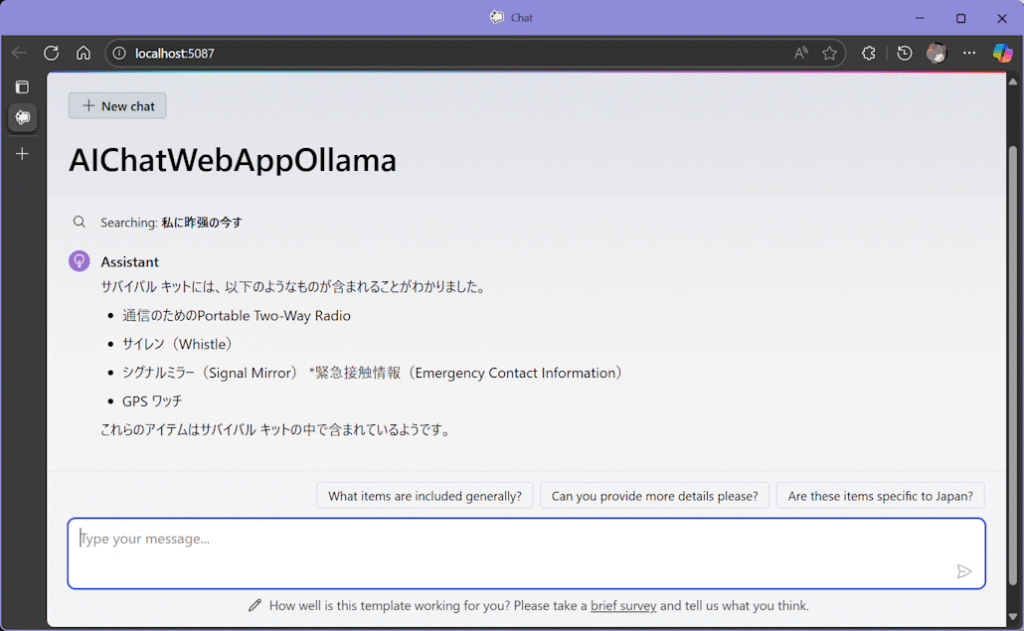
というような感じで、PDFの内容から回答を引っ張ってきている。「Searching」の日本語が、入力した質問と全く違い、変な日本語になっているのはLLMの問題か?
wwwroot\Data下におくPDFファイルを別のものに置き換えたり、UIを適当にいじったりすれば、それなりのAI Chatアプリケーションにはなりそう。
ただし、ollamaを使用すると回答を得るまでにかなり時間がかかるね。モデルのせいかもしれないけれど・・・
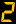
 Users Today : 2
Users Today : 2 Users Yesterday : 37
Users Yesterday : 37 Users Last 7 days : 186
Users Last 7 days : 186 Users Last 30 days : 1080
Users Last 30 days : 1080 Users This Month : 1009
Users This Month : 1009 Users This Year : 4357
Users This Year : 4357 Total Users : 98872
Total Users : 98872 Views Today : 3
Views Today : 3 Views Yesterday : 46
Views Yesterday : 46 Views Last 7 days : 239
Views Last 7 days : 239 Views Last 30 days : 1280
Views Last 30 days : 1280 Views This Month : 1203
Views This Month : 1203 Views This Year : 5260
Views This Year : 5260 Total views : 137706
Total views : 137706 Who's Online : 0
Who's Online : 0
9/29 プロジェクトテンプレートのインストール方法を追加